

Leaf是美团在分布式ID生成算法——雪花算法的基础上提出的一种分布式ID生成算法。它具备全局唯一、高可用、高并发、低延迟以及简单接入(通过HTTP或公司内部RPC)的优点。
Twitter:世界上不存在两片一样的雪花。
美团:世界上不存在两片一样的树叶。
╮(╯_╰)╭
leaf算法一共有两种分布式ID生成模式,分别是号段模式、雪花ID模式。这也是目前主流的两种生成分布式ID的方式。
leaf算法——号段模式
号段模式下,ID从低位增长,较少的号段浪费,能够容忍MySQL短时不可用。leaf的号段模式也不断的在优化,一共经历了预分发号段、双Buffer优化、动态步长三个阶段。
预分发号段 采用预分发方式生成ID,一个DB上挂N个server。每个server启动时,从DB取固定长度的ID list,数据库只持久化一批ID中最大的一个。用户通过轮训方式调用各个leaf server的服务,因此一个client获取到的ID序列可能是1,1001,1002,2…。某个server的号段用完后,下一次请求就会从DB加载新的号段,保证每次加载的号段是递增的。但是如果更新DB号段时,DB宕机或者发生主从切换,会导致一段时间的服务不可用;且系统的最大耗时取决于更新DB号段的时间。
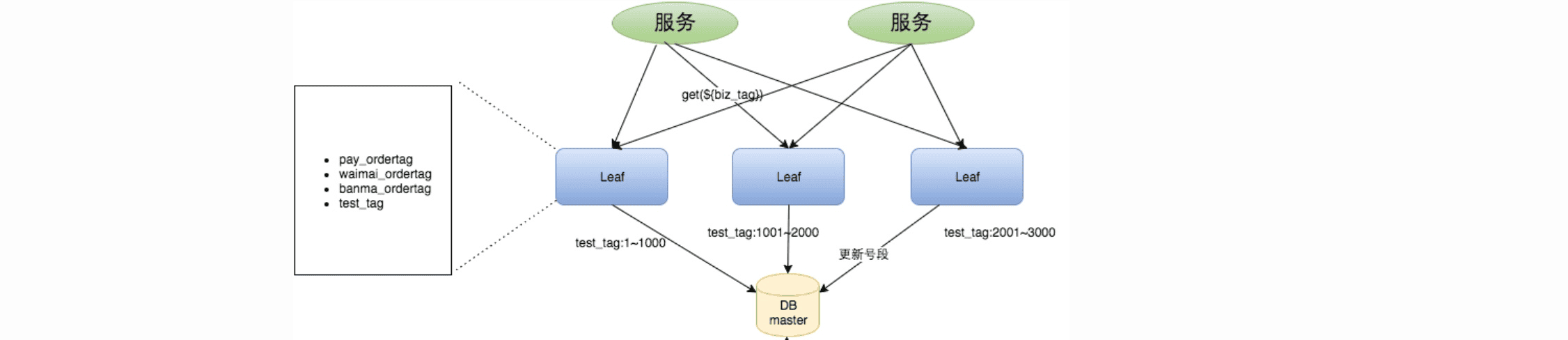
双buffer优化 为了解决上面问题,leaf采用异步更新。一个server分为两个buffer,并轮流对外提供服务。双buffe优化可以保证无论何时DB出现问题,都有一个buffer可以正常向外提供服务。只要DB在一个buffer的下发周期内恢复,就不会影响整个leaf的可用性。但是,在这个版本中号段长度是固定的,如果本来leaf在DB不可用的情况下能够支持10min,若流量增加10倍就只能支持1min。
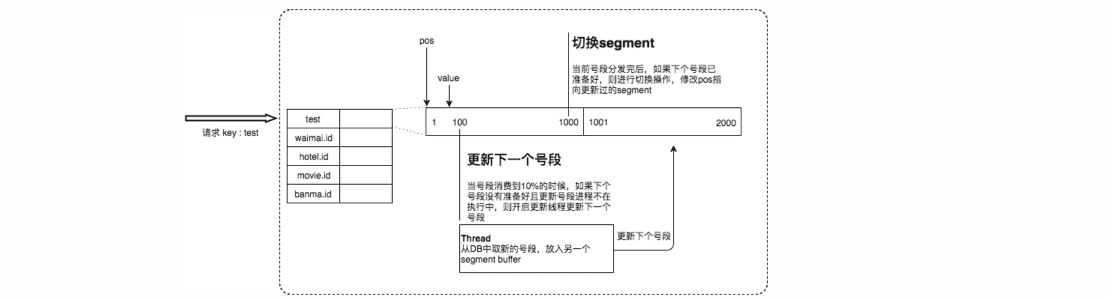
动态步长 根据上一次的更新周期T和号段长度step来决定这一次更新的号段长度,T<15分钟则step=step*2,1530则step=step/2。
至此,满足了号段消耗稳定趋于某个时间区间的需求。当然,面对瞬时流量几十、几百倍的暴增,该种方案仍不能满足可以容忍数据库在一段时间不可用、系统仍能稳定运行的需求。因为本质上来讲,Leaf虽然在DB层做了些容错方案,但是号段方式的ID下发,最终还是强依赖DB的。
leaf算法——雪花ID模式
雪花ID模式和雪花算法大差不差,详细的可以看链接中的雪花ID。
此外,Leaf提供了Java版本的实现,同时对Zookeeper生成机器号做了弱依赖处理,即使Zookeeper有问题,也不会影响服务。Leaf在第一次从Zookeeper拿取workerID后,会在本机文件系统上缓存一个workerID文件。即使ZooKeeper出现问题,同时恰好机器也在重启,也能保证服务的正常运行,做到了对第三方组件的弱依赖。
相关链接:
分布式ID生成算法—leaf算法
https://www.lanzlz.cn/archives/166
评论