
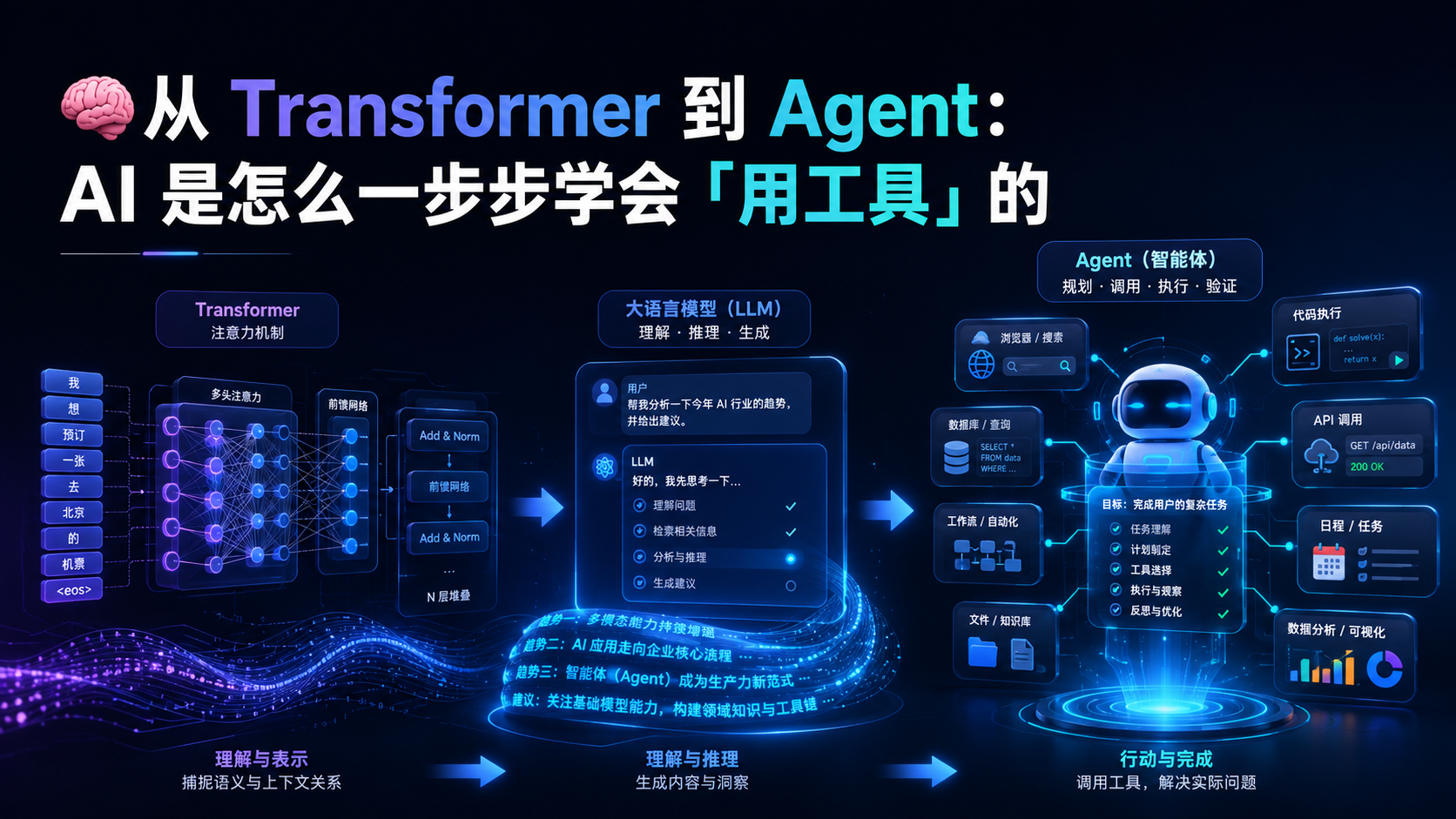
置顶从 Transformer 到 Agent:AI 是怎么一步步学会「用工具」的
AI能力进化路径清晰:从仅预测文本的Transformer(封闭概率生成系统,无行动能力)到Function Calling(工具接口化),再到ReAct(边想边做,获得过程意识与动态决策),最终演进为Agent——围绕LLM构建的执行系统,集成规划器、工具层、记忆层与循环执行。Agent的关键转变是从“回答问题”到“完成任务”,具备多步执行、外部系统调用、状态管理及可恢复执行,标志着AI从“生成器”跃迁为“执行器”。工业界已进入Agent工程时代,开发、企业系统、办公产品广泛应用,未来将向多Agent协作系统发展。核心是:Transformer解决理解语言,Agent解决改变现实。
置顶OpenClaw:跨平台 AI 智能体 Gateway,让 AI 接入一切通信渠道
OpenClaw是一款AI智能体网关系统,旨在解决AI智能体如何无缝接入各种通信平台并统一管理的问题。它通过提供跨平台消息接入、AI Agent网关、自动化工作流和浏览器自动化能力,使企业能够快速构建多渠道AI应用。OpenClaw的核心价值在于一次开发,多平台运行,统一AI接入层,自动化业务流程,构建AI Agent生态。随着AI技术的发展,OpenClaw这样的AI Gateway平台可能成为未来企业AI架构中的关键组件。


LangChain 实战指南:从零开始构建你的第一个 AI Agent
大模型进入工程化落地阶段后,能调用工具、执行任务、完成工作流的 AI Agent 比纯聊天式 AI 更具价值。本文利用 LangChain 从零构建最小可运行 Agent,包含自定义工具(加法计算器、用户查询),并解析其核心机制:LLM 推理判断、工具选择、执行与结果反馈循环。同时给出可复用的四文件项目结构(app/llm/tools/agent)及企业级架构演进路径。文章指出常见陷阱(工具过多、Prompt 不稳、缺权限控制、长链路性能差),并从 LangChain Agent 到 LangGraph 再到企业 Agent 平台推荐升级方向。核心结论:AI Agent 的真正价值在于赋予模型执行能力,而非仅增强回答能力。
拆开神经网络的黑箱:从反向传播到 Transformer
本文系统介绍了神经网络的核心原理与发展脉络:反向传播通过链式求导把误差逐层传回,是训练深度网络的关键;卷积神经网络利用局部连接和权重共享高效处理图像;RNN、LSTM/GRU与Transformer则分别面向序列建模,最终以自注意力机制实现并行计算。文章还总结了Batch Norm、残差连接、学习率调度等训练技巧,以及预训练+微调范式如何降低NLP门槛,推动BERT、GPT等模型广泛应用。


换个思路看机器学习:当代码不再是一行一行写出来的
文章用程序员视角讲解了机器学习的本质:传统编程是“写规则”,机器学习是“喂数据,让模型自动学习规则”。训练本质上是通过损失函数和梯度下降不断自动调参,神经网络则是多层函数和矩阵运算的堆叠。文中还用软件工程类比了模型、过拟合、特征工程、推理等概念,并强调 ML 项目更难的往往不是算法,而是数据、部署、监控和工程化落地。最后指出,机器学习不是黑魔法,而是一种新的开发工具和编程范式。
程序员的下一站:从“写代码的人”到“构建系统的人”
文章指出,近两年程序员的焦虑源于职业价值来源的迁移:过去“会写代码”就有竞争力,如今框架成熟、低代码和AI降低了编码门槛,普通执行型程序员的价值被压缩。未来更有竞争力的是技术专家和系统型工程师,他们不仅要会写代码,更要具备抽象能力、架构能力、业务理解、AI应用和项目交付能力。代码仍是基础,但核心竞争力正从“写代码”转向“设计系统、组织系统、定义问题”,程序员行业将出现明显分层和极化。


DeepSeek V4 预览版深度解析:百万上下文 + Agent 时代的国产大模型标杆
DeepSeek V4 预览版发布,核心亮点是百万级上下文、原生 Agent 能力和国产算力深度适配。V4 分为 Pro 与 Flash:Pro 主打顶级推理、代码与世界知识能力,Flash 更快更便宜,适合日常对话和轻量任务。其采用 DSA 稀疏注意力与 Token 压缩,实现 1M 上下文可用,并兼容 OpenAI 与 Anthropic 接口,迁移成本低。旧接口将于 2026 年 7 月 24 日停用,开发者需尽快切换。
Qwen3.6-Plus:迈向真实世界的 AI 智能体
阿里通义千问发布 Qwen3.6-Plus,标志大模型从“被动应答”迈向“主动执行”的智能体阶段。该模型重点强化智能体编程与工具调用,在 SWE-bench、Terminal-Bench 2.0 等测试中表现领先,尤其在真实终端环境任务上取得 61.6 分。它还支持 100 万 token 超长上下文,提升了长文档和代码仓库处理能力,并增强了图像、视频理解与 GUI Agent 场景应用。模型兼容 OpenAI 与 Anthropic API,推动“Vibe Coding”开发体验,但仍面临闭源和行业竞争压力。


美团砸 260 亿放大招!每天白送 5500 万 Token,普通人零成本薅 AI 羊毛
美团作为本地生活服务巨头,投入260亿研发AI,推出5500万免费Token,开放LongCat大模型调用。此举旨在推动AI在本地生活的应用,降低成本,吸引开发者共建生态。普通人可通过平台申请Token,用于日常办公、学习、开发等场景。美团通过AI优化服务,提升效率,同时沉淀数据,迭代能力,为用户提供更多价值。